
Meta has teamed with Cerebras on AI inference in Meta’s new Llama API, combining Meta’s open-source Llama models with inference technology from Cerebras. Developers building on the Llama 4 Cerebras model in the API can expect speeds up to 18 times faster than traditional GPU-based solutions ….
News Bytes 20250407: Tariffs and the Technology Industry, Intel-TSMC Deal?, DARPA Taps Wafer Scale, Sandia and Laser-Based Cooling, Optical I/O News
April 8, 2025 by

Good April day to you! It was a wild week for more than the HPC-AI sector last week, here’s a brief (7:39) look at some key developments: U.S. tariffs, the technology sector and advanced chips, Intel-TSMC ….
DARPA Taps Cerebras and Ranovus for Military and Commercial Platform
April 2, 2025 by

AI compute company Cerebras Systems said it has been awarded a new contract from the Defense Advanced Research Projects Agency (DARPA) to develop a system combining their wafer scale technology with wafer scale co-packaged optics of Ottawa-based Ranovus to deliver ….
Cerebras Reports Fastest DeepSeek R1 Distill Llama 70B Inference
February 3, 2025 by
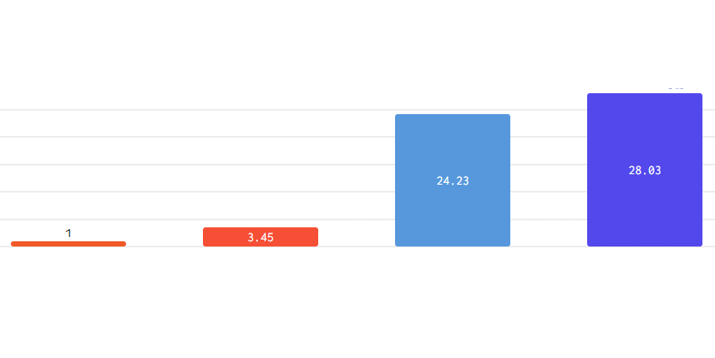
Cerebras Systems today announced what it said is record-breaking performance for DeepSeek-R1-Distill-Llama-70B inference, achieving more than 1,500 tokens per second – 57 times faster than GPU-based solutions. Cerebras said this speed enables instant reasoning capabilities ….
Cerebras Wafer-Scale Cluster Brings Push-Button Ease and Linear Performance Scaling to Large Language Models
September 21, 2022 by
Cerebras Systems, a pioneer in accelerating artificial intelligence (AI) compute, unveiled the Cerebras Wafer-Scale Cluster, delivering near-perfect linear scaling across hundreds of millions of AI-optimized compute cores while avoiding the pain of the distributed compute. With a Wafer-Scale Cluster, users can distribute even the largest language models from a Jupyter notebook running on a laptop with just a few keystrokes. This replaces months of painstaking work with clusters of graphics processing units (GPU).

