Today, MLCommons announced new results for its MLPerf Inference v5.0 benchmark suite, which delivers machine learning (ML) system performance benchmarking. The rorganization said the esults highlight that the AI community is focusing on generative AI, and that the combination of recent hardware and software advances optimized for generative AI have led to performance improvements over the past year.
To view the results, visit the Datacenter and Edge pages.
The MLPerf Inference benchmark suite, which encompasses datacenter and edge systems, is designed to measure how quickly systems can run AI and ML models across a variety of workloads. The open-source and peer-reviewed benchmark suite creates a level playing field for competition that drives innovation, performance, and energy efficiency for the entire industry.
It also provides critical technical information for customers who are procuring and tuning AI systems. This round of MLPerf Inference results also includes tests for four new benchmarks: Llama 3.1 405B, Llama 2 70B Interactive for low-latency applications, RGAT, and Automotive PointPainting for 3D object detection.
The Inference v5.0 results show that generative AI scenarios have gained momentum. Over the last year submissions have increased 2.5x to the Llama 2 70B benchmark test, which implements a large generative AI inference workload based on a widely-referenced open-source model. With the v5.0 release, Llama 2 70B has now supplanted Resnet50 as the highest submission rate test.
The performance results for Llama 2 70B have also grown since a year ago: the median submitted score has doubled, and the best score is 3.3 times faster compared to Inference v4.0.
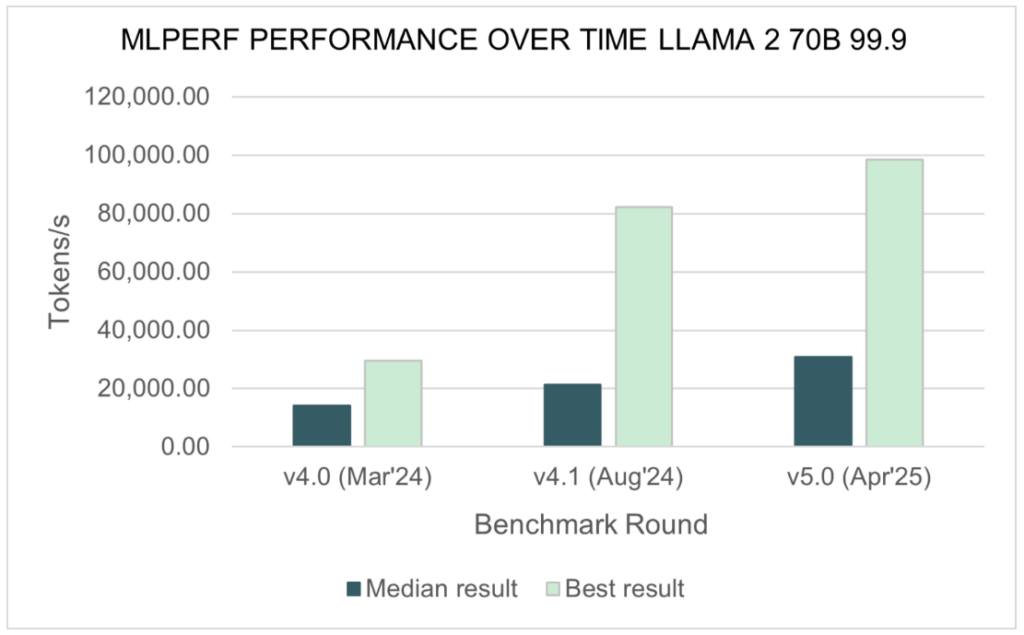
source: MLCommons
“It’s clear now that much of the ecosystem is focused squarely on deploying generative AI, and that the performance benchmarking feedback loop is working,” said David Kanter, head of MLPerf at MLCommons. “We’re seeing an unprecedented flood of new generations of accelerators. The hardware is paired with new software techniques, including aligned support across hardware and software for the FP4 data format. With these advances, the community is setting new records for generative AI inference performance.”
The benchmark results for this round include results for six newly available or soon-to-be-shipped processors:
- AMD Instinct MI325X
- Intel Xeon 6980P “Granite Rapids”
- Google TPU Trillium (TPU v6e)
- NVIDIA B200
- NVIDIA Jetson AGX Thor 128
- NVIDIA GB200
In step with advances in the AI community, MLPerf Inference v5.0 introduces a new benchmark utilizing the Llama 3.1 405B model, marking a new bar for the scale of a generative AI inference model in a performance benchmark. Llama 3.1 405B incorporates 405 billion parameters in its model while supporting input and output lengths up to 128,000 tokens (compared to only 4,096 tokens for Llama 2 70B). The benchmark tests three separate tasks: general question-answering, math, and code generation.
“This is our most ambitious inference benchmark to-date,” said Miro Hodak, co-chair of the MLPerf Inference working group. “It reflects the industry trend toward larger models, which can increase accuracy and support a broader set of tasks. It’s a more difficult and time-consuming test, but organizations are trying to deploy real-world models of this order of magnitude. Trusted, relevant benchmark results are critical to help them make better decisions on the best way to provision them.”
The Inference v5.0 suite also adds a new twist to its existing benchmark for Llama 2 70B with an additional test that adds low-latency requirements: Llama 2 70B Interactive. Reflective of industry trends toward interactive chatbots as well as next-generation reasoning and agentic systems, the benchmark requires systems under test (SUTs) to meet more demanding system response metrics for time to first token (TTFT) and time per output token (TPOT).
“A critical measure of the performance of a query system or a chatbot is whether it feels responsive to a person interacting with it. How quickly does it start to reply to a prompt, and at what pace does it deliver its entire response?” said Mitchelle Rasquinha, MLPerf Inference working group co-chair. “By enforcing tighter requirements for responsiveness, this interactive version of the Llama 2 70B test offers new insights into the performance of LLMs in real-world scenarios.”
More information on the selection of the Llama 3.1 405B and the new Llama 2 70B Interactive benchmarks can be found in this supplemental blog.
Also new to Inference v5.0 is a datacenter benchmark that implements a graph neural network (GNN) model. GNNs are useful for modeling links and relationships between nodes in a network and are commonly used in recommendation systems, knowledge-graph answering, fraud-detection systems, and other kinds of graph-based applications.
The GNN datacenter benchmark implements the RGAT model, based on the Illinois Graph Benchmark Heterogeneous (IGBH) dataset containing 547,306,935 nodes and 5,812,005,639 edges.
More information on the construction of the RGAT benchmark can be found here.
The Inference v5.0 benchmark introduces a new Automotive PointPainting benchmark for edge computing devices, specifically automobiles. While the MLPerf Automotive working group continues to develop the Minimum Viable Product benchmark first announced last summer, this test provides a proxy for an important edge-computing scenario: 3D object detection in camera feeds for applications such as self-driving cars.
More information on the Automotive PointPainting benchmark can be found here.
“We rarely introduce four new tests in a single update to the benchmark suite,” said Miro Hodak, “but we felt it was necessary to best serve the community. The rapid pace of advancement in machine learning and the breadth of new applications are both staggering, and stakeholders need relevant and up-to-date data to inform their decision-making.”
MLPerf Inference v5.0 includes 17,457 performance results from 23 submitting organizations: AMD, ASUSTeK, Broadcom, Cisco, CoreWeave, CTuning, Dell, FlexAI, Fujitsu, GATEOverflow, Giga Computing, Google, HPE, Intel, Krai, Lambda, Lenovo, MangoBoost, NVIDIA, Oracle, Quanta Cloud Technology, Supermicro, and Sustainable Metal Cloud.
“We would like to welcome the five first-time submitters to the Inference benchmark: CoreWeave, FlexAI, GATEOverflow, Lambda, and MangoBoost,” said David Kanter. “The continuing growth in the community of submitters is a testament to the importance of accurate and trustworthy performance metrics to the AI community. I would also like to highlight Fujitsu’s broad set of datacenter power benchmark submissions and GateOverflow’s edge power submissions in this round, which reminds us that energy efficiency in AI systems is an increasingly critical issue in need of accurate data to guide decision-making.”
“The machine learning ecosystem continues to give the community ever greater capabilities. We are increasing the scale of AI models being trained and deployed, achieving new levels of interactive responsiveness, and deploying AI compute more broadly than ever before,” said Kanter. “We are excited to see new generations of hardware and software deliver these capabilities, and MLCommons is proud to present exciting results for a wide range of systems and several novel processors with this release of the MLPerf Inference benchmark. Our work to keep the benchmark suite current, comprehensive, and relevant at a time of rapid change is a real accomplishment, and ensures that we will continue to deliver valuable performance data to stakeholders.
MLCommons is the world’s leader in AI benchmarking. An open engineering consortium supported by over 125 members and affiliates, MLCommons has a proven record of bringing together academia, industry, and civil society to measure and improve AI. The foundation for MLCommons began with the MLPerf benchmarks in 2018, which rapidly scaled as a set of industry metrics to measure machine learning performance and promote transparency of machine learning techniques. Since then, MLCommons has continued using collective engineering to build the benchmarks and metrics required for better AI – ultimately helping to evaluate and improve AI technologies’ accuracy, safety, speed, and efficiency.

