
Computer Vision
Computer Vision is a field of artificial intelligence (AI) and computer science that focuses on enabling machines to interpret, understand, and analyze visual data from the world around us. The goal of computer vision is to create intelligent systems that can perform tasks that normally require human-level visual perception, such as object detection, recognition, tracking, and segmentation. Computer vision involves a wide range of techniques and approaches, enabling models to learn from large amounts of visual data, such as images and videos. There have been many recent achievements in computer vision, driven in large part by advances in deep learning and neural networks.
Here are a few notable examples:
- GPT-3 Image Generation: The GPT-3 language model, developed by OpenAI, has recently been used to generate realistic images from textual descriptions. By conditioning the neural network on natural language descriptions, the model is able to generate detailed images that accurately capture the described scene.
- Object Detection: The latest state-of-the-art object detection models achieve high accuracy on a variety of datasets, including COCO, Pascal VOC, and ImageNet. These models are based on deep learning architectures such as Faster R-CNN, RetinaNet, and YOLOv5, and use techniques such as feature pyramids and anchor boxes to improve accuracy and speed.
- Autonomous Vehicles: Computer vision is a key technology for enabling autonomous vehicles to navigate and interpret their environment. Recent advances in this area include NVIDIA’s DRIVE AGX platform, which uses deep learning algorithms to enable real-time perception and decision-making for autonomous vehicles.
- Medical Imaging: Computer vision is also being used to improve medical imaging, with recent advances including AI-based systems for diagnosing lung cancer and detecting diabetic retinopathy.
- Robotics: Computer vision is critical for enabling robots to perceive and interact with the world around them. Recent advances include deep learning-based systems for object recognition, visual grasping, and manipulation.
Computer vision is an active and rapidly developing field, with many new techniques and applications constantly emerging. It has the potential to revolutionize many industries and transform the way we interact with machines and the world around us. Let’s look at some common tasks that computer vision help solved in modern days and that could be applied across many business domains:
- Object detection: identifying and locating objects within an image or video
- Image recognition: classifying images based on their content
- Facial recognition: identifying and verifying the identity of a person based on their facial features
- Autonomous vehicles: enabling vehicles to navigate and interpret their environment using visual data
- Medical imaging: analyzing medical images to detect and diagnose diseases
- Augmented reality: overlaying digital information onto real-world images or videos
- Retail and E-commerce: to improve product recommendations and visual search
- Agriculture: to improve crop yield and reduce crop damage
Of course, Computer vision also has its own challenges. One of the main is the need for large amounts of annotated data to train accurate models. Collecting and annotating large datasets can be expensive and time-consuming, and often requires specialized expertise. Furthermore, different tasks and domains may require different types of data and annotations, making it difficult to reuse existing datasets.
Transfer learning
Transfer learning addresses these challenges by allowing us to reuse pre-trained models and datasets for new tasks and domains. By using a pre-trained model as a starting point (often called back-bone model), we can reduce the amount of new data and annotations required to train a new model and improve the performance of the new model on the target task. The concept of transfer learning in machine learning and the human brain is related, but the underlying mechanisms and processes are different.
- In machine learning, transfer learning involves the use of pre-trained models that have already been trained on a large dataset for a specific task. These models are then fine-tuned on a smaller dataset for a related task, allowing them to learn and adapt more quickly to the new task. This process can significantly improve the efficiency and accuracy of the learning process, as the pre-trained models have already learned to recognize certain features and patterns that can be applied to the new task.
- In contrast, transfer learning in the human brain refers to the ability of humans to apply knowledge and skills learned in one context to another context. For example, someone who has learned to play the piano may find it easier to learn to play another instrument, like the guitar, because they have already developed some relevant skills and knowledge that can be transferred to the new context. This ability to transfer knowledge and skills between different contexts is a fundamental aspect of human learning and intelligence.
Pre-trained neural networks
There are several pre-trained neural networks that have gained significant popularity and have been widely used in various computer vision applications. Here are some of the most famous ones:
VGG: VGG (Visual Geometry Group) is a family of deep neural networks that achieved top performance in the 2014 ImageNet Challenge. The VGG models are characterized by their deep architecture, with up to 19 layers, and have been widely used for various computer vision tasks, such as object recognition and localization.
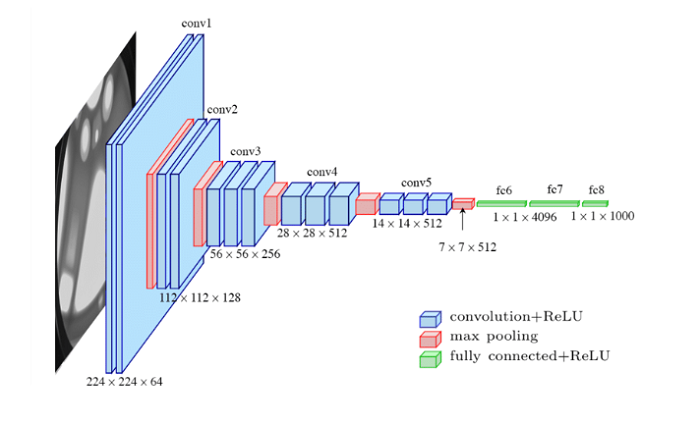
ResNet: ResNet (Residual Network) is another family of deep neural networks that won the ImageNet Challenge in 2015. ResNet models are characterized by their residual blocks, which allow for easier training of very deep neural networks with over 100 layers. ResNet models have been widely used for various computer vision tasks, such as object recognition and detection.
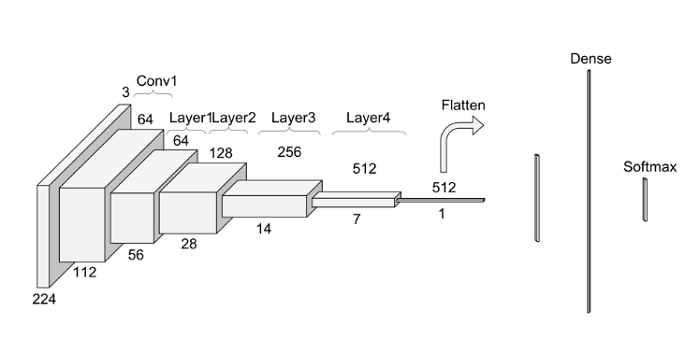
Inception: Inception is a family of deep neural networks that was introduced by Google in 2014. The Inception models are characterized by their use of multiple parallel convolutional layers at different scales to extract features from images. Inception models have been widely used for various computer vision tasks, such as image classification and object detection.
MobileNet: MobileNet is a family of deep neural networks that was designed for mobile and embedded devices with limited computing resources. MobileNet models are characterized by their lightweight architecture, which enables fast inference on mobile devices. MobileNet models have been widely used for various computer vision tasks, such as object recognition and detection on mobile devices.
These pre-trained neural networks have been made publicly available and have been widely used as a starting point for transfer learning in many computer vision applications. You can find more information about different models on TensorFlow Model Garden and PyTourch Hub the two most popular deep learning frameworks.
Training locally and in the cloud
When it comes to training large visual models, there are benefits to both training locally and in the cloud. Training locally allows you to have complete control over the hardware and software used for training, which can be beneficial for certain applications. You can select the specific hardware components you need, such as graphics processing units (GPUs) or tensor processing units (TPUs) and optimize your system for the specific training task. Training locally also provides more control over the training process, allowing you to adjust the training parameters and experiment with different techniques more easily. However, training large visual models locally can be computationally intensive and may require significant hardware resources, such as high-end GPUs or TPUs, which can be expensive. Additionally, the training process may take a long time, potentially several days or even weeks, depending on the size of the model and the complexity of the dataset.
Training in the cloud can provide several benefits, including access to powerful hardware resources, such as TPUs and GPUs, and scalability. Cloud providers like Amazon Web Services (AWS), Google Cloud Platform (GCP), and Microsoft Azure offer cloud-based machine learning platforms that provide pre-configured environments for training and deploying machine learning models. Cloud-based platforms also allow you to easily scale up or down based on the size of the dataset and the complexity of the model, providing cost-effective solutions for both small and large projects. However, training in the cloud can also come with additional costs, such as data transfer and storage costs, and may require some additional setup and configuration. Additionally, there may be security and privacy concerns when using cloud-based services, so it’s important to ensure that your data is protected and handled in compliance with any applicable regulations.
Use Cases
To better ‘feel’ how transfer learning work, let’s dive deeper at specific use case from retailers/fashion domain. Suppose a retail company wants to improve its product recommendation system by suggesting similar products to customers based on some preferences. The company has a large catalog of product images and wants to create an accurate and efficient recommendation system that can learn from customer behavior and feedback. You can read about one such model in more details, including python code, on GitHub report Fashion-Recommendation-System.
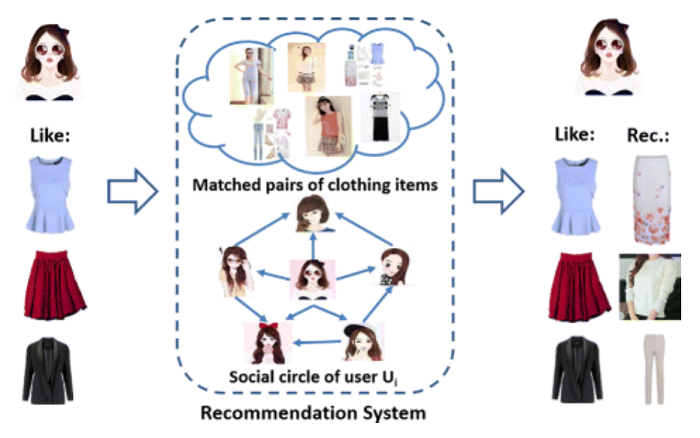
One way to accomplish this is to build your recommendation model from scratch, but this will cost a lot of resources, so instead, the company can use a pre-trained convolutional neural network (CNN) model like VGG, which has already been trained on a large dataset of images.
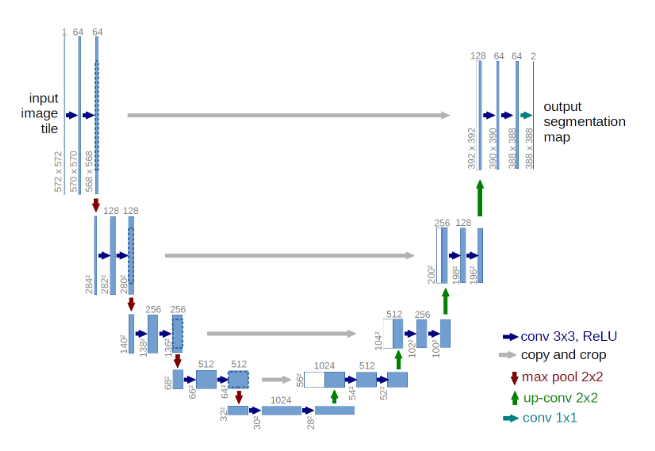
The pre-trained CNN can be fine-tuned on the retail company’s product images to recognize general or even specific features and attributes of the products, such as color, texture, shape and which will be related specifically to the company’s product images and not to general image set.
Once the pre-trained CNN has been fine-tuned on the retail company’s product images, it can be used to generate embeddings for each product. These embeddings represent the unique features of each product that the model has learned to recognize. The embeddings can then be used to compare and find similarities between products.
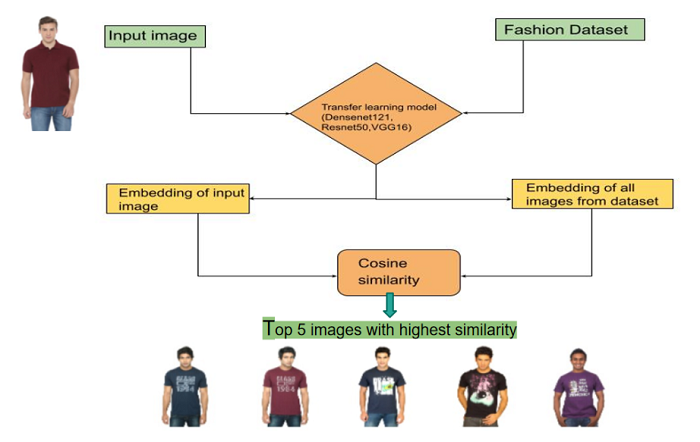
Generally, embedding is not in the human readable form (like color, texture), but instead they are represented as weight coefficients of the last layer of the neural network. And the most popular way to find similarities in such form is to use cosine distance. You can find more details including full code implementation based on the FCNNs, U-Net neural network on the Kaggle notebook (Get Started With Semantic Segmentation).
In results, when a customer interacts with the recommendation system, their behavior and preferences are recorded, and their embeddings are generated. The system then compares the customer’s embeddings with the embeddings of the company’s product catalog and suggests products that are most like the customer’s preferences.
Summary
Summarizing all above, we can see that transfer learning has been shown to be an effective technique in improving the performance of computer vision models in various business applications. By leveraging pre-trained models, transfer learning allows businesses to significantly reduce the amount of labeled training data required for training and fine-tuning their models. This can result in significant cost savings and faster time-to-market for new products and features. In e-commerce, transfer learning can be used to improve product search and recommendation systems, automate product tagging and categorization, and enable visual search capabilities. Transfer learning can also be used to improve image and video analysis for tasks such as product quality control and visual inspection.
While there are challenges to implementing transfer learning in different business domains, such as finding and adapting the right pre-trained models to the specific domain and dataset, the benefits are significant. By leveraging transfer learning, businesses can improve the accuracy and efficiency of their computer vision models, leading to better customer experiences and increased revenue.
Useful Links
https://github.com/mj703/Fashion-Recommendation-System
https://www.kaggle.com/code/rajkumarl/get-started-with-semantic-segmentation/notebook
https://keras.io/api/applications/
https://github.com/tensorflow/models/tree/master/official
https://keras.io/api/applications/
About the Author

Ihar Rubanau is a Senior Software Developer at Sigma Software Group. He’s an experienced IT professional with a decade of industry expertise and 15 years focused on Data Science. His projects revolve around time-series analysis, anomaly detection, and recommendation engines. Ihar specializes in neural networks and possesses interdisciplinary knowledge in fields such as history, astrobiology, and computational molecular evolution. With roles ranging from Data Analyst to Financial Analyst, he has delivered notable projects in Brain-Computer Interfaces, Signals Processing, and Dating. Ihar continues to push boundaries in Data Science with innovative solutions.
Sign up for the free insideAI News newsletter.
Join us on Twitter: https://twitter.com/InsideBigData1
Join us on LinkedIn: https://www.linkedin.com/company/insidebigdata/
Join us on Facebook: https://www.facebook.com/insideAI NewsNOW


